

Walk through any 2,000-acre corn operation during planting season and you'll see the same thing: precision planters generating terabytes of yield data, irrigation systems logging moisture readings every hour, procurement teams tracking fertilizer costs in spreadsheets, and equipment managers using WhatsApp to coordinate maintenance schedules. Meanwhile, the "AI dashboard" that promised to revolutionize farm operations sits mostly unused because nobody trusts what it's telling them.
The disconnect isn't about the AI being bad. It's about farms trying to force AI onto data systems that evolved organically over decades without any real governance framework. You end up with procurement teams making fertilizer orders based on last year's Excel files while the AI system recommends something completely different based on satellite imagery nobody verified.
This breakdown happens because farms approach AI adoption backwards—they buy the technology first, then wonder why it doesn't magically fix their operational problems. What actually works is building staged data governance that matches your existing procurement cycles and operational rhythms, then layering AI capabilities only where the data foundation can support them.
The hidden cost structure of ungoverned farm data
Most mid-size farms lose somewhere between $40-80 per acre annually just from data coordination failures before AI even enters the picture. These aren't dramatic system crashes—they're death by a thousand cuts across procurement, field operations, and harvest logistics.
Take fertilizer procurement. A typical 3,000-acre operation might order around $450,000 worth of nitrogen annually. Without centralized data governance, the procurement manager pulls last year's application rates from one system, checks current soil tests from another database that only updates quarterly, and compares prices from suppliers through email chains. By the time the order gets placed, field conditions have changed, but that information sits trapped in the field manager's tablet.
The result? Over-application in some zones costing roughly $15,000 in wasted product, under-application in others reducing yield by 7-9 bushels per acre. The AI system that was supposed to optimize this process recommended the right rates, but nobody trusted its recommendations because the underlying data came from three different sources with different update frequencies.
Equipment coordination breaks down the same way. Your combine harvesting corn generates yield maps showing exactly which field zones underperformed. The planting crew needs this data to adjust seed populations next season. But if yield data lives in the combine's proprietary system, seed recommendations come from the agronomist's software, and the planter gets programmed through yet another interface, you've created an operational nightmare that no amount of AI can fix.
Labor allocation during harvest shows this problem clearly. Without unified data governance, harvest crews work off weather forecasts from their phones, equipment availability from text messages, and field moisture readings from whenever someone last checked. The farm's AI system might perfectly predict optimal harvest timing, but if crews don't trust or can't access those predictions in the field, you're still making decisions the old way while paying for new technology.
Why traditional IT governance fails on farms
Corporate data governance frameworks collapse when applied to agricultural operations. The MBA-approved approach of creating data dictionaries, establishing single sources of truth, and implementing rigid approval workflows sounds great in theory. In practice, it means telling your field manager they can't update irrigation schedules until the data governance committee meets next Tuesday.
Take control of your farm’s productivity.
Feldsly helps you plan, track, and optimize every farming operation with precision.
- Centralized crop scheduling
- Resource & labor management
- Real-time weather alerts
No credit card required
Farm operations don't pause for governance meetings. When aphids appear in your soybean fields, you need to coordinate scouting data, threshold calculations, and spray decisions within hours, not wait for standardized data formats. This operational tempo breaks traditional governance approaches that work for banks or manufacturers.
The seasonal nature of agriculture makes this worse. During planting or harvest, every operational system runs at maximum capacity. There's no bandwidth for data cleanup projects or governance training. But during winter months when you theoretically have time for these projects, key seasonal staff aren't available and the urgency disappears.
Geographic distribution adds another layer. A single corn operation might span 30 miles with fields under different weather patterns, soil types, and even time zones for larger operations. Trying to implement uniform data standards across this geographic spread ignores the reality that your western fields might need completely different operational parameters than eastern ones.
Most importantly, farms mix ultra-modern and decades-old systems by necessity. Your new John Deere combine generates precise yield maps, but your functional 1995 grain truck doesn't have GPS. Forcing everything into a single data standard means either abandoning useful legacy equipment or creating manual data entry nightmares that defeat the purpose of automation.
Building governance that matches farm operations
Instead of trying to transform everything at once, successful farms build data governance in stages tied to natural operational cycles and procurement patterns. This approach starts with high-value, low-complexity data flows and expands only after proving value at each stage.
First stage: Procurement data foundation
Start with procurement because it has clear ROI metrics and manageable data volumes. Focus initially on three data streams: fertilizer and chemical purchase history, seed variety performance by field, and equipment parts and maintenance costs.
For a 2,500-acre operation, this might mean standardizing how you track roughly $290,000-$320,000 in annual input costs across 3-4 major suppliers. Create simple data standards—product codes, field identifiers, date formats—that your procurement team can actually maintain. The goal isn't perfection; it's consistency good enough to spot patterns like paying 8% more for the same fertilizer from different suppliers.
Set quality gates that match procurement reality. If fertilizer invoices don't match field application records within 5%, flag it for review. But don't reject the entire dataset—farm operations can't wait for perfect data reconciliation.
Second stage: Field operations integration
Only after procurement data flows smoothly do you expand to field operations. Connect application records to procurement data so you know not just what you bought, but where it went and when. This reveals gaps like the 300 gallons of herbicide that got delivered but never appears in any spray records.
Add basic QA thresholds that make operational sense. If spray records show 32 gallons per acre when the label maximum is 24, flag it immediately. If planting populations vary more than 15% from prescribed rates, investigate why. These aren't AI decisions yet—they're data quality checks that build trust in the system.
The metrics at this stage focus on data completeness, not optimization. Track what percentage of field operations have complete records, how quickly data moves from field to system, and whether operational teams actually use the data for decisions.
Third stage: Yield and performance correlation
With procurement and operations data flowing reliably, you can start correlating inputs to outputs. This is where AI begins adding value, but only for specific, bounded problems. Don't try to optimize everything—pick one critical decision like nitrogen application rates where better data governance could save $25,000-$35,000 annually.
Here's a simple workflow visualization of staged governance to AI deployment.
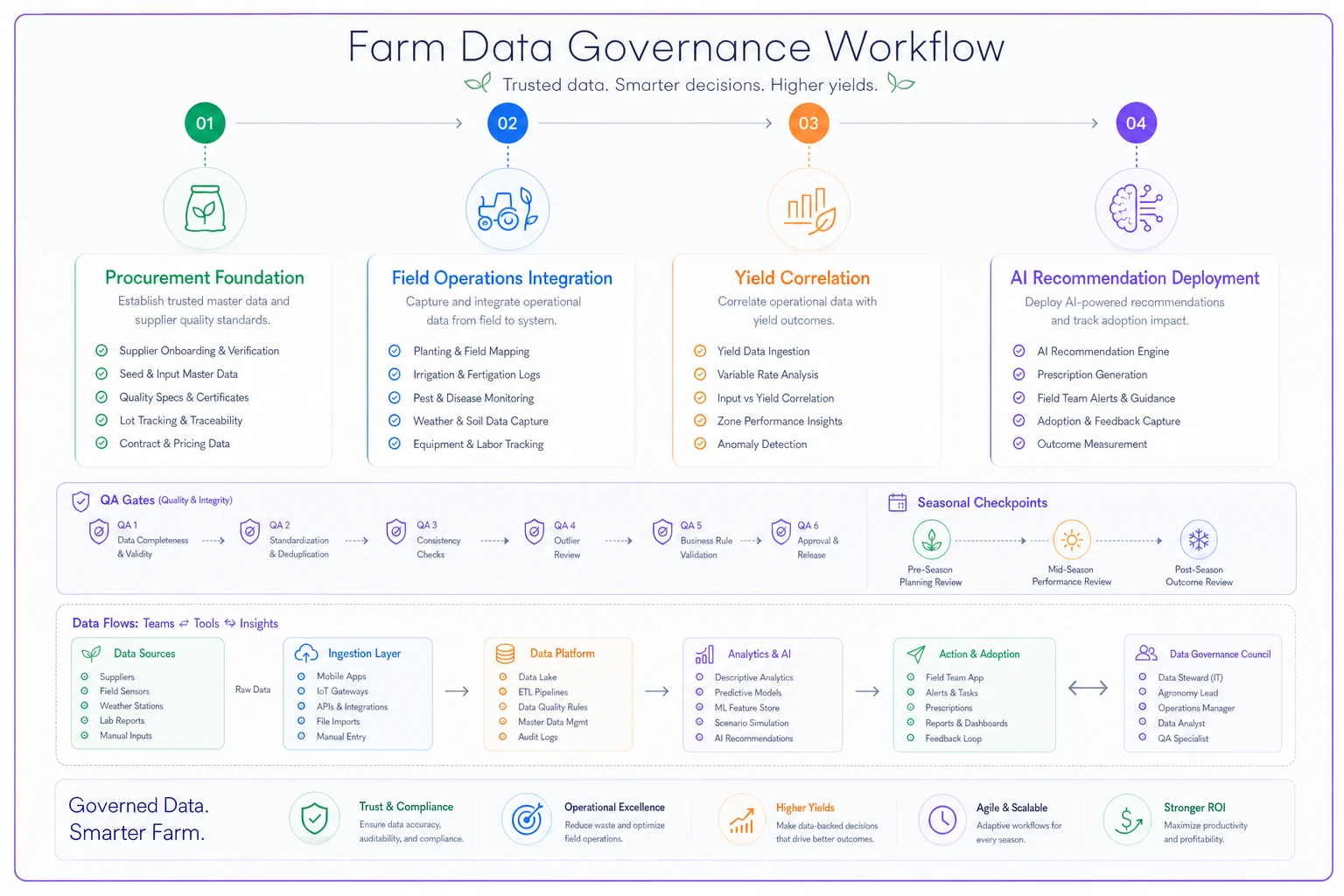
Build trust through staged rollouts. Run AI recommendations parallel to human decisions for a full season without acting on them. Show field managers how the AI would have decided differently and what the outcome would have been. When they see the AI correctly predicting that fields with 2% more organic matter needed 18-22 pounds less nitrogen, trust builds naturally.
Building QA gates that match agricultural reality
Quality assurance in farm data can't work like manufacturing QA where you reject anything outside specifications. Agricultural data is inherently messy—weather changes, equipment breaks, and biological systems don't follow rigid rules. Your QA gates need to separate "different but valid" from "actually wrong."
Start with range-based validation tied to agronomic reality. Corn populations between 28,000 and 36,000 plants per acre are normal variation. Below 22,000 or above 38,000 triggers investigation. This catches data entry errors (typing 320,000 instead of 32,000) without flagging normal operational variation.
| QA Level | Response | Example Issue | Impact on Operations |
|---|---|---|---|
| Level 1 | Auto-correct | Missing field ID | None - silent fix |
| Level 2 | Alert only | Application rate 20% outside normal | Flag for review |
| Level 3 | Halt processing | Physically impossible values | Requires resolution |
Implement graduated responses to QA failures. Level 1 issues get auto-corrected based on GPS coordinates. Level 2 issues generate alerts but don't stop operations. Level 3 issues halt processing until resolved. This prevents the "boy who cried wolf" problem where every minor issue becomes a crisis.
Tie QA windows to local agronomic norms and seasonal calendars so you don't flag valid regional practices as errors.
Most critically, tie QA metrics to operational outcomes, not data purity. Track whether flagged issues actually impacted yield, not whether every field has perfectly formatted identifiers. A field labeled "North 40" instead of "FieldN40" doesn't matter if everyone knows what it means and the data flows correctly.
Pilot metrics that predict full-scale success
The metrics that matter during pilots aren't the ones that matter at full scale. Pilot success depends on adoption, trust-building, and proving the concept works.
Pilot phase metrics (first 90 days):
-
Data ingestion rate
What percentage of operational data successfully enters the system? For fertilizer procurement, aim for around 80% of invoices digitized within 48 hours.
-
Decision alignment rate
How often do AI recommendations match experienced operator decisions? Early on, 55-65% alignment is good.
-
Time-to-insight
How quickly can the system answer basic operational questions? "What was our nitrogen cost per bushel last season?" should take minutes, not hours.
-
User interaction frequency
Daily logins mean it's useful. Weekly means it's supplemental. Monthly means it's failing.
Expansion phase metrics:
-
Process time reduction
If generating fertilizer orders took 6 hours before and takes 4 hours with AI assistance, that's tangible value.
-
Error reduction rate
A 25-35% reduction in procurement errors saves both money and relationships with suppliers.
-
Recommendation acceptance rate
This should climb from around 20% early on to 60-70% as trust builds.
Full-scale success requires ROI, efficiency, and reliability.
ROI thresholds tied to agricultural economics
Agricultural ROI calculations need to reflect the industry's thin margins and seasonal cash flows. A 2% improvement in gross margins might sound trivial to tech companies but represents survival versus bankruptcy for many farm operations.
Set different ROI thresholds for different operational areas based on their impact and risk. Procurement optimization should deliver 4-7% cost savings within one buying cycle because the data is controlled and decisions are reversible. Yield optimization through variable rate applications might only need 3-5% improvement because the dollar impact per percentage point is much higher.
Account for temporal ROI patterns. Fertilizer optimization might save $30,000 in Year 1 through better procurement timing but only $15,000 in Year 2 once easy wins are captured. Equipment maintenance prediction might show negative ROI in Year 1 during system training but prevent a $95,000 harvest delay in Year 2.
Include risk reduction in ROI calculations, not just cost savings. If better data governance helps you avoid one failed herbicide application that would have required complete field retreatment at $45 per acre across 500 acres, that $22,500 risk mitigation counts toward ROI even if it's not guaranteed savings.
Create graduated rollout triggers based on achieved ROI. If your first stage delivers 3% cost reduction, expand cautiously. At 5%, accelerate rollout. Above 8%, dedicate more resources. Below 2%, pause and diagnose problems before expanding.
Connecting governance stages to seasonal workflows
Trying to implement data governance during peak operational seasons is like asking your team to rebuild the engine while driving down the highway. The biggest mistake farms make is ignoring operational rhythms when planning governance rollouts.
Map governance rollout to operational valleys. Implement procurement data standards in late fall after harvest but before next year's input planning. Roll out field operations tracking in late winter when crews have time for training. Add yield correlation analysis during the quiet period between planting and first chemical applications.
Build data collection into existing workflows rather than creating new ones. If scout reports already go through WhatsApp, add a simple form that captures structured data from those same messages. If equipment operators already do pre-shift checks, add data logging to that existing routine. The less behavior change required, the more likely adoption succeeds.
Design governance processes that respect seasonal labor patterns. Your full-time staff might handle complex data validation, but seasonal workers need simple, error-proof collection methods. A harvest truck driver can select from 5 field options on a tablet, but asking them to enter GPS coordinates will fail.
Create seasonal checkpoints for governance assessment. After planting, audit what data got captured and what got missed. Post-harvest, analyze which governance processes survived peak season stress and which broke down. These natural breaks provide reflection time without disrupting operations.
The compound effect of staged data maturity
Each governance stage multiplies the value of previous stages, but only if you resist the temptation to skip ahead. This compound effect means the difference between 10% and 90% data governance isn't 9x value—it's closer to 100x because complete data enables entirely new operational capabilities.
With just procurement data governed, you can optimize buying timing and vendor selection, worth maybe $20,000 annually on a 2,000-acre farm. Add field operations data and you can optimize application rates and timing, adding another $30,000 value. Connect yield data and suddenly you can do prescription agriculture with confidence, potentially adding $70,000 through yield optimization. But try to jump straight to prescription agriculture without the foundation and you'll waste $50,000 on technology that doesn't deliver.
This compounding shows up in operational coordination too. Clean procurement data means you know what inputs you have. Connected to field operations, you know what's been applied where. Add equipment data and you can predict when you'll run out based on actual application rates and remaining acres. Add weather data and you can optimize application timing around forecast windows. Each layer enables more sophisticated decision-making, but only if previous layers are solid.
Trust compounds the same way. When procurement teams see real savings from better data, they become advocates for field operations to participate. When field operations see benefits, they push for equipment integration. This organic adoption driven by proven value beats any top-down mandate.
The compound effect also applies to problems. Bad procurement data pollutes field operations analytics. Unreliable field data makes yield correlation worthless. One broken link in the governance chain invalidates everything downstream, which is why staged rollout with quality gates at each stage matters so much.
Common failure patterns in farm AI governance
Understanding how farm data governance typically fails helps you avoid the most expensive mistakes. These patterns repeat across operations of all sizes because they reflect fundamental tensions between agricultural operations and data systems.
The "shiny object" failure happens when farms chase the latest AI capability without building underlying data governance. You implement yield prediction AI while still tracking yields on paper, then wonder why predictions don't match reality. The AI isn't wrong—it's working with wrong data. This pattern wastes both the technology investment and erodes team trust in all data-driven decisions.
The "perfect is the enemy of good" failure occurs when farms design elaborate governance frameworks that never get implemented. Spending six months designing the perfect field naming convention while continuing to lose $5,000 monthly from procurement inefficiencies means you prioritized theoretical purity over practical value. Agricultural operations need "good enough" governance that actually gets used, not perfect systems that exist only in documentation.
The "IT drives agriculture" failure inverts the proper relationship between operations and technology. When IT departments design governance without understanding that rain doesn't wait for data validation, you get systems that technically work but operationally fail. Your governance needs to follow agricultural rhythms, not force agriculture to follow IT schedules.
The "all or nothing" failure tries to govern everything simultaneously. Attempting to standardize data across procurement, operations, equipment, weather, and yield in one massive project guarantees failure. Teams get overwhelmed, nothing gets properly implemented, and the whole initiative collapses.
A few months back, our operations manager caught an $18,000 discrepancy by accident when comparing fertilizer invoices to application records. The supplier had been billing us for premium nitrogen while delivering standard grade for three months. Without basic procurement data governance, we would have never spotted it—and honestly, we got lucky someone noticed at all. That one catch paid for our entire first-stage data governance implementation.
Building team buy-in through graduated automation
The technical side of data governance is actually easier than the human side. Your team needs to trust that better data governance helps them do their jobs better, not replaces them or adds bureaucratic burden.
Start automation with recommendation systems, not decision-making systems. Let the AI suggest fertilizer rates, but keep the agronomist in control of final decisions. Show how AI recommendations compare to current practices and let the team judge whether they make sense. Trust builds when people see the technology enhancing their expertise rather than replacing it.
Make data entry as painless as possible. If field managers already walk through each field weekly, give them a tablet that auto-fills GPS coordinates and field names. If they're already taking photos of problem areas, add a quick dropdown to categorize issues. The goal is capturing operational data without changing operational workflows.
Create feedback loops that show immediate value. When better procurement data helps secure a 4% volume discount from your fertilizer supplier, make sure the team knows. When AI-optimized spray timing prevents a reapplication that would have cost $12,000, communicate that success. People support what they see working.
Phase in governance requirements gradually. Start with voluntary data entry and basic analytics. Once teams see value, add simple validation rules. Only after trust is established do you implement more restrictive governance policies that could slow operations.
Modern AI-powered operational software makes this transition smoother by automating data collection wherever possible and providing immediate value even from incomplete data sets. The key is building governance that supports better decision-making rather than creating bureaucratic overhead that slows down time-sensitive agricultural operations.
Ready to revolutionize your farm management?
Join 500+ farms using Feldsly to boost yields, reduce waste, and streamline daily farm workflows.